A/B Testing for the Mathematically Disinclined
Online, testing is king. A/B testing is a simple, scientific way to test variables in the real world.
Online, testing is king. A/B testing is a simple, scientific way to test variables in the real world.
Many marketers test and measure variations of their marketing efforts. They spend countless hours focusing on campaign improvements but considerably less thought on improving the Web site.
It’s as if Web sites weren’t as fluid and malleable as AdWords or Overture campaigns or you could only change a site during a redesign. At a recent conference, I asked attendees if they were aware of A/B testing. Almost all the hands went up. When I asked how many actually do A/B testing, very few hands rose in response.
Almost everyone buys into the theoretical value of testing. Few would argue with Claude Hopkins, author of “Scientific Advertising” (1923), who wrote, “Almost any question can be answered cheaply, quickly and finally, by a test campaign. And that’s the way to answer them — not by arguments around a table. Go to the court of last resort — buyers of your products.”
Hopkins couldn’t market on the Internet, but you certainly can — and should. We work in a medium where testing really is king. It’s incredibly easy and can yield powerful results. Online, marketers may be in the driver’s seat, but consumers are doing all the steering.
One of the absolute best ways to continuously improve the performance of your Web site is to use split testing, also called A/B split testing. A/B testing is a simple, scientific way to isolate and test variables in a real-world environment.
A/B testing is like my recent eye exam. The ophthalmologist had me stare through a machine and answer, “Which picture is sharper and easier to read, A or B?” I’d choose between the two, and he would make a small change. Then he would again ask, “A or B?” Each time, he made another small adjustment, always taking the better result. This continued until I could see clearly through the machine.
The problem with the eye test analogy is a doctor has population studies that establish the test’s controls. The eye chart scales and the machines he uses are carefully calibrated to ensure accurate, predictable, replicable results.
One of my favorite test examples is one Amazon.com conducted well over a year ago. Below is the “ready to buy” area on its pages.
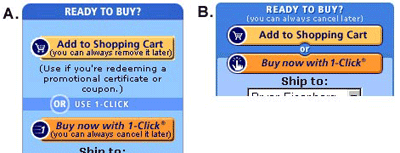
The original site always used version A. The book section of the site removed that phrase from the buttons (version B). I’m not privy to the objectives behind the test, and I always recommend adding assurances at the point of action (POA), but for a long time you could still find versions of button A on other areas of Amazon’s site.
ICE.com conducted a test using a Visual Sciences tool. It wanted to increase sales of featured products listed on its home page. It decided to test the copy beneath the featured product and measure the effect. It tested three variations against the control (no copy). The four variations:

Which do you think outperformed the others? As is often the case in A/B testing, we fall in love with one idea and will it to be the winner. A/B testing provides real-world, data-driven, unbiased answers to a hypothesis. Early indications showed version D to be the hands-down winner. It resulted in thousands of dollars of increased spending. However, as the group sample size grew, results fizzled out and the test became insignificant. (There is a problem with this test’s execution. If you know what it is, email me.)
How can you tell if results are valid? When you run any kind of test, beware the “fresh” factors: seasonality, even time of day. You must run tests concurrently, ideally for a couple of weeks. Be certain your sample size is adequate and results variation between tests is statistically meaningful.
Mike Sack, executive VP of Inceptor, an A/B testing platform, offers some tips on how to set things up:
First step is to decide in what proportion you are going to split your traffic, 50/50, 90/10, or even 80/20. And you can split them randomly, by time of day or even by source (Google people to A and Yahoo to B). Second, you must decide on test stability; in other words, if a visitor leaves your site and comes back, do they see the same test? You can choose for no stability, session stability, and cookie stability. At a minimum, you should have session stability, even though cookie stability is better for tracking latent conversions.
Finally, you need to decide your sample size and set up the criteria for success. To decide your ultimate sample size, run a “null” test with your A/B test. The null test is really just an A/A test, where you are running the control against itself to determine where the convergence of results matches up (typically within 0.05 percent of each other, but that’s up to you). When the tests converge, you’ll have an idea of the volume of traffic you need to test. You decide your criteria for success based on a certain number of conversions or sales, or you can measure results over course of time (two weeks). To be sure your test is showing a statistically meaningful impact on the variables, you have to know if you’ve demonstrated enough of a difference (delta) between the tests to declare a clear winner. As a rule of thumb, you should have at least a three times larger result (e.g., if A is 5, B should be 15).
A/B testing is powerful and there are all kinds of ways do it: using inexpensive scripts; routing traffic to different servers; using software and services that set up A/B testing services, such as Inceptor, Optimost, OfferMatica, and Visual Sciences. You may wield the power to test thousands of variables, but remember only a few have significant effect on return on investment (ROI). Although tools make it simple to test, they don’t provide the knowledge, hard work, and resources it takes to build successful tests. That part’s up to you.






