Are content thieves harming your search rankings?
Sites which scrape and copy content from others are sometimes able to outrank the original source and damage their search rankings. What can be done about it?
Sites which scrape and copy content from others are sometimes able to outrank the original source and damage their search rankings. What can be done about it?
Sites which scrape and copy content from other websites are often able to outrank the original source, as the examples below will demonstrate.
These content cheats are sometimes able to do damage to the original site’s rankings, causing a loss of search visibility, and potentially lost sales and leads.
The examples here also call into question the effectiveness of Google’s handling of content scrapers. At the moment, it does look like Google is unable to recognize the original source of content consistently, and this can be a real problem for content creators.
Along with Pi Datametrics, we devised a test last year to see how easy it was to disrupt another site’s rankings by copying their content. So, let’s look at the results of these tests and discuss what publishers can do to combat the problem.
Note: the examples used here are from Google.co.uk.
The idea for the this test came when Pi noticed the volatility of one of their client’s search rankings.
After some investigation, they found the cause was copied content.
This is a site that offers luxury African safari holidays. To improve its SEO and provide useful information for visitors, the site produced some well-researched content for its pages.
Here’s one example:

This was produced exclusively for Journeys by Design, but this copy was lifted word-for-word and used by another website which also offers safari holidays.
Since then it has been copied by at least three other sites. Here’s one:

In theory, Google should be able to spot the original source of the content and ensure that the copycat site doesn’t rank above the original for related searches. However, that hasn’t happened here.
The chart below shows how the site’s search rankings have been disrupted by others using their content.
It shows the search rankings for the term “mountain gorilla’s nest” over an eight month period.
The blue line shows Journeys by Design, while the other lines are from the copycat sites.

Though the original site has had the most consistent ranking for the term over this period, several of the copycat sites were also able to rank at various times.
These copycat sites also outranked the original, causing Journeys by Design to slip down past position 100 for days and weeks at a time.
This is a loss of traffic and opportunity which has commercial implications, as searchers looking for safari holidays would be unable to find the site with one of its target terms, thanks to the copycats.
After noticing this, Pi decided to set up a test to see how easy it would be to rank for stolen content.
Generally speaking, these copycat sites are weaker because they have fewer links and less valuable content – apart from that which was lifted from elsewhere that is.
So, would this mean that any weak site can simply steal content from stronger rivals and outrank them?
For the first test, Pi took an interview on PPC strategy that was posted on Econsultancy – my old site – and published it on their Intelligent Positioning blog. This content was copied word-for-word, with permission of course.
For searches on the article title, we can see that the copied version briefly interrupts the original’s search position.

However, on searches for a more generic term, like “PPC strategy,” Pi was able to outrank the original, as shown by the red line.
The chart suggests that Google didn’t know which one should rank for a while, with positions swapping for a few days, but the copied article won out in the end.

The same test was carried out using ClickZ content. In this case, a guest post from 2012 by Bryan Eisenberg on web form optimization.
Once again, the content was copied word-for-word, with an image featuring a note to explain.

The results of this test are interesting, as it didn’t interrupt ClickZ‘s rankings as much as in the two previous examples.
After the article was copied, the original still ranks reasonably consistently for the phrase “online web form optimization”.

What’s odd is that the copied version also ranks in the top three positions for the same term, at the same time.
If you look closely, you’ll notice the dips in early September correspond to the peaks in ClickZ‘s search rankings. It is having an effect on ClickZ‘s position, but not as much as we might have expected.

However, the troughs from August 20 do correspond to the peak of another site: Bryan Eisenberg’s blog.
Bryan published his ClickZ post in full on his own blog, and had been enjoying some decent search visibility for the same search term. Although this was before the copied article was published.

Since then, Bryan’s post virtually vanished from the SERPs for this term, and now it’s replaced by the version copied from ClickZ for the test.

For a while, the copycat version outranked the original ClickZ version, taking second place on Google U.K.
Meanwhile, the ClickZ article is five places below, and Bryan Eisenberg’s version isn’t even in the top 100 positions.

So once again, a copycat site was able to mess with the search rankings of the original content producers, outranking them for periods of time.
Once the copied version has been removed from the Intelligent Positioning blog, I expect that ClickZ will return to the top two or three positions on Google. What happens to Bryan’s version of the post remains to be seen.
These tests were carried out on Google UK (with more to follow using .com) and the differences between the US and UK versions of Google are interesting.
For example, while the IP blog was able to disrupt Bryan Eisenberg’s UK rankings copied content, it couldn’t achieve the same effect in the US SERPs.
It did manage to rank for a short time, but my guess is that a combination of the other two sites’ authority and their US location knocked the British pretender back down again.

Also, Bryan’s version of the post did continue to outrank ClickZ, yet Google still allows both versions to rank highly.
Since then, I’ve seen a few examples of scraper sites outranking ClickZ at times.
Here’s one example. A scraper site is outranking the ClickZ original.
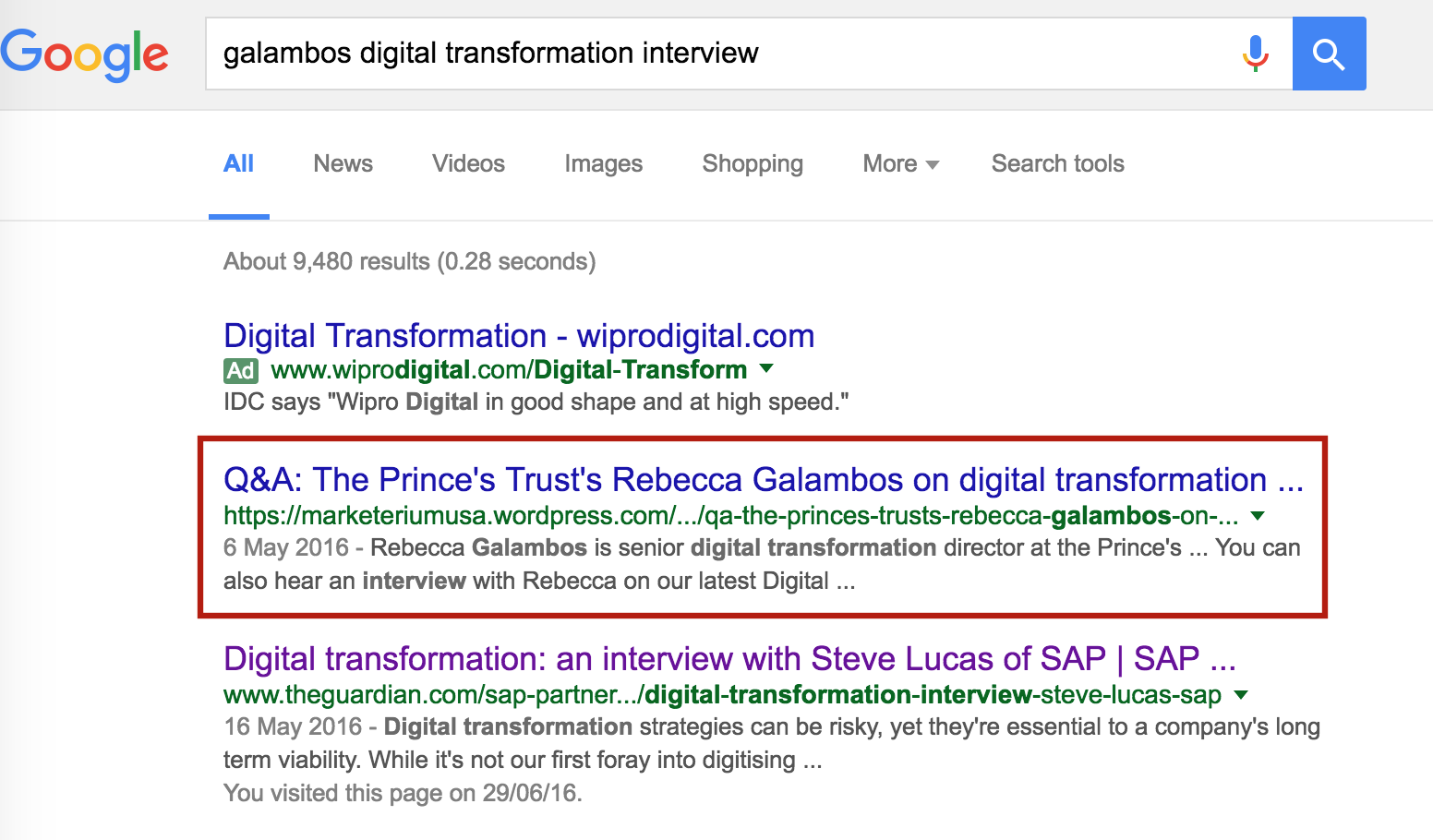
Ok, the term ‘galambos digital transformation interview‘ isn’t going to bring in floods of visitors (I’m probably the only person ever to have searched for that) but it is worrying that this ay be happening for other phrases.
Content is massively important for achieving SEO goals and driving traffic to sites, as well as leads and sales in many cases.
After taking the time and energy to work on composing a useful article, it is annoying to find that another site can simply steal it and reap the SEO benefits from your content.
Indeed, this test underlines the importance of monitoring the performance of content long after publication, so you can take action against the copycats if you find them.
In addition, it may also have implications for things like product copy used across multiple sites, which is something retailers do a lot.
There are a few measures that sites can take when they find copied content:
.@mattcutts I think I have spotted one, Matt. Note the similarities in the content text: pic.twitter.com/uHux3rK57f
— dan barker (@danbarker) February 27, 2014
In addition, the Bryan Eisenberg example provides a lesson for sites that accept guest posts. It’s worth ensuring that contributors don’t republish their articles in full on their own sites as this may affect your own rankings.
I’ve generally to publish extracts and point back to the original, thus avoiding this issue. Or you ask them to use the rel=canonical link to indicate the original post.
An obvious conclusion is that this is an area where Google needs to improve. If copying of content is allowed to work like this, even if just for a short time, then it provides an incentive for the scrapers to use this tactic.
It does seem that Google’s method of dealing with this issue is inconsistent. For instance, in the ‘PPC strategy’ example earlier in this post, the original and copycat sites swap positions frequently, as if Google isn’t able to determine which is the copycat site.
As Pi Datametrics’ Jon Earnshaw explains:
Having content stolen can be an extremely frustrating and costly issue. It looks like there is a flaw in Google’s algorithm when it deals with duplicate content.
The best thing to do is track your terms and see if others are harming your site. You can only see this flipping of positions if you have daily URL tracking. If you see unexplained fluctuations, then digging deeper, ultimately you can report the abuser to Google.
The examples here tell us that copycat content can be an issue for sites, which can result in loss of traffic and potential sales through no fault of their own.
It also tells us that the copycats can win. They may not be able to rank consistently, but they can reach high search positions simply by cheating. If they achieve this at key times of the year (the holiday shopping season for instance) then it can damage the original site.
I’d hope that Google’s handling of copied content improves overtime, but I’d say that sites need to be aware of this issue so they can take action to minimize the potential effects.






