Ideas and how we share them: can AI save social?
There has been a lot of talk in the recent past about the ‘demise of Twitter’. Will the platform continue in the future, or will it slide slowly into irrelevancy?
It’s a complicated question, but not one without precedent. One only has to look at the fortunes of MySpace to realise that no social platform is too big to fail.
I have always believed one of the key issues is that new users find Twitter confusing. Onboarding is a struggle because in an attempt to drive new connections and higher ad revenue, the company focuses on ‘mainstream’ content.
TV shows, large sporting events, huge movie or music releases. While these are undeniably important talking points, this approach plunges a user into a torrent of content with no means to easily separate solid commentary from noise (Chris Lake commented extensively on this in his excellent post earlier this year).
Unable to find depth, new users become disenchanted with the experience and leave, while advertisers are encouraged to push towards ever-wider audiences, reducing relevancy and response (But increasing the coffers of the ad platforms themselves, at least in the short term).
This issue isn’t unique to Twitter. Noise is on the increase across every platform, as businesses attempt to adopt publishing models, and ad-based businesses fail to evolve past ‘put more pop-ups on everything’ thinking.
As Doug Kessler put it in his excellent presentation, the internet is in danger of drowning in a torrent of ‘crap content’. I genuinely believe that in the near future, we’ll all be looking at hiring full-time ‘accelerators’ who take charge of lighting a fire under our content distribution.
If we’re all accelerating though, how do we help our audiences cut through that huge wave of distribution and get to the stuff that really matters to them?
In the nascent days of social media (And here I’m talking about the fully-formed, Facebook-and-Twitter-and-LinkedIn platforms, rather than obscure Arpanet forums) sharing was easy and multifaceted.
Users shared content and links, but also thoughts and events. Each user had a certain amount of reach, so that reach was a transferable commodity.
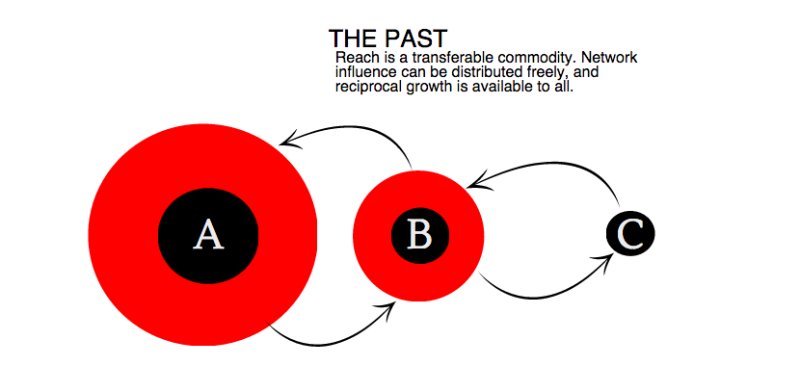
User A shared something with user B. User B shared this with User C, who in turn followed user A, and recommended user B, and everyone’s reach and authority increased incrementally, depending on the quality of their output and the time they dedicated to their network. Your ability to become an influencer was regulated by the knowledge you were able to share.
In this climate, being an expert (or at least being able to give the impression you were one) was valuable. Knowledge = recognition = reach. This model allows ideas to travel freely around various networks. A lot has been written about networks that behave this way in the past, but it is the next part of this evolution that I feel is particularly interesting for the digital industry here.
As this model propagated, a new behaviour appeared, and not from individual users. Eager for content, publishers began both producing their own content, and also curating the knowledge and content of others.
Because of their ability to invest in push media, certain sources became ‘Important’. They became influencers in their own right. And because of this, information introduced to the network could not spread easily unless it was verified by these influencers
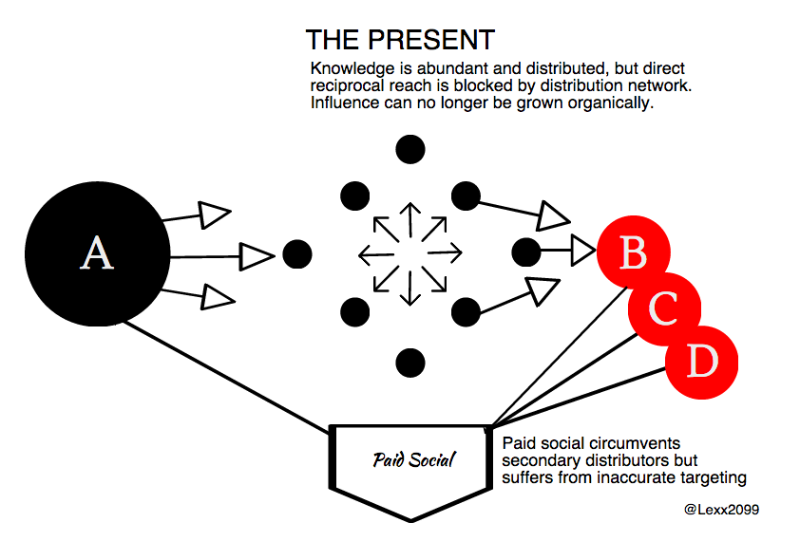
This does not mean that influencers are a bad thing. Having influence in a sector is always of worth, but it also encourages bias.
The more your sources converge around the same pieces of knowledge, the less room there is for disruptive voices and ideas. We see this every day in broadcast media, and while there is room to drive great good, it’s often a divisive force.
These certainly aren’t new ideas. In the recent past the writers Christopher Vitale and Warren Ellis have discussed the above in some depth, while Jim A. Kuypers talks extensively about proximity creating bias in journalism in his book Partisan Journalism: A History of Media Bias in the United States.
Essentially, journalists who bunk together tend to develop similar narratives because they are all exchanging notes. The same thing occurs in social networks. When noise reaches saturation point, ideas cannot rise based on merit, only on endorsement.
This leaves us with a new, and interesting state of affairs. The source is no longer the primary influencer. We have a radical abundance of knowledge. I’m sure you’ve all heard stats about the rising levels of data creation.
Since 2013, we’ve pumped out more data than during the entire history of the human race, but it’s currently sitting in silos and servers, unread and unusable. If we want to distribute ideas effectively, we need an adaptable, systematic network.
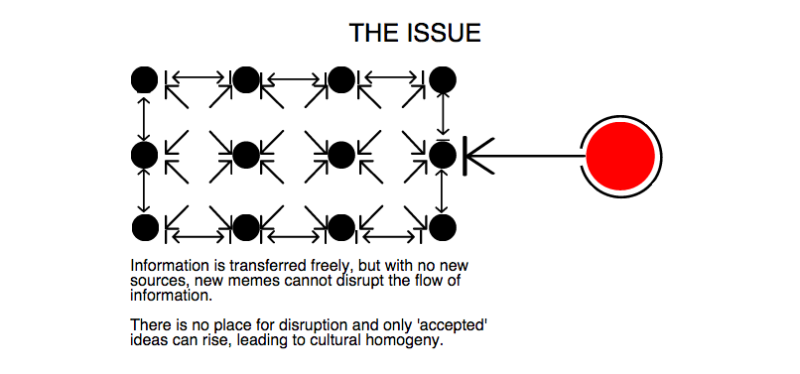
This means that new platforms that rely on gimmicks are not the solution. Character limits, or lack of ads, or even privacy are not the fundamental reasons people share things. They share because they find something to be emotionally affecting.
But once they have seen this too many times, that emotional effect is negated, and they lose interest. New ideas are critical to sharing.
This is where things get really interesting. Last year I attended a talk by Kevin Ashton, who spoke about the future of connectivity in cities, and Milton Keynes’ “MKSsmart” project in particular.
Cities have always generated a lot of noise. Radio and TV, traffic and phones. But smart cities harness a new layer of information, generated from sensors, phones and wearables that are tied in with existing infrastructure to allow the city to adapt to the needs of the ‘user’.
You do not need to listen out for a traffic report when you can watch each and every car as it clusters at red lights. Rather than avoid this traffic, drivers can be automatically rerouted through traffic signals and satnavs, or alerted when parking spaces become available. These are small changes that have massive effects on traffic jams and therefore fuel usage.
There are plenty of working examples of this, from complete, advanced projects like Masdar City project in Abu Dabi, or Japan’s Tsukuba Science City, designed to utilise technology in every surface, to the retrofitting of Glasgow and Bristol with sensor clusters designed to automate simple tasks (If you are interested in this, then I suggest you check out this marvelous post by Matt Jones,which looks at these themes in far more depth).

This project also offers us a nice analogy. The social networks of the future need to monitor their own traffic flows more efficiently, and allow new ideas and information to be onboarded and distributed more effectively. We already have speed, but we lack efficiency in distribution.
Marketing automation may be a precursor to this, with dynamic content and messaging delivered in response to user actions, but there is far more to be done.
Again using it purely as an example, Twitter has always been mooted as a ‘Town Hall’. Everyone comes together and discusses a topic. But in reality town halls are not permanently open, and the discussions they hold are moderated around single topics and debate.
Twitter’s town hall is now too open to be effective. Too much noise and too much content has the same consequences everywhere.
Now let’s look at Reddit. Where thousands of tightly moderated communities exist alongside one another. Users are free to hop into other communities, as long as they aren’t trying to talk about London in a New York subreddit.
The one thing missing from this is a method of discovering not only those new communities, but the specific content within them, as it is required. Better search functions can help (Possibly alongside the ability to switch from content based on what your network is sharing, to content that is being shared by curated sources outside that network), but we need a dynamic medium.
We must be able to write to platforms actively as well as consume the content they offer passively. We need the platform as a platform.
Social network providers have a ridiculous amount of data on users. Six or seven years of browsing and clicking and retweeting and sharing habits should be more than enough for Twitter to map conversations to me directly, and serve them up as I am discussing something. But currently we rely on targeting that uses primitive identifiers like bio keywords.
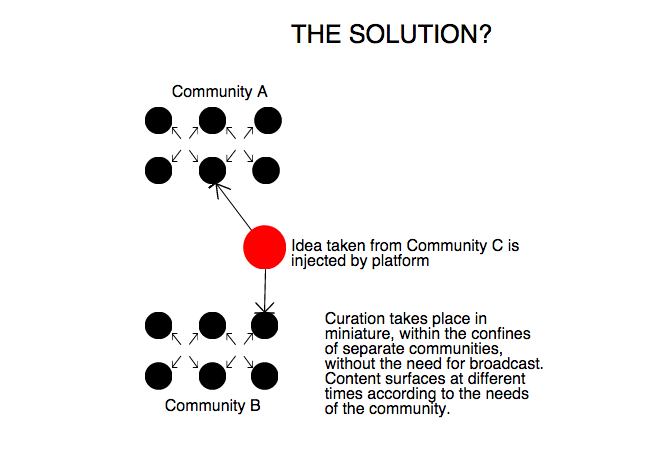
Instead, we should be thinking about utilising people directly as system architecture, monitoring and matching advertisers ever more closely to target audiences, with publishers acting as roving ‘town halls’, adding ideas to discussions as and when they are needed.
There is so much more to say on this, and I think much of it ties into the rise of various post-capitalist economic models. While the Blockchain might not accomplish it, it does posit some interesting new ideas on the nature of ‘value’ which will become more important.
I often think that social media acts as an outlier of things to come. The move towards content and then intent marketing have both begun there, but this is a much bigger issue.
AI is beginning to offer some hope, and may yet prove to be the saviour of online publishers (And you should definitely check out the recent ClickZ podcast on this, because it’s going to be increasingly important in the next year), but until platforms themselves start integrating this technology efficiently then we’re going to have a rocky ride.
I certainly don’t pretend to have all the answers (or even all of the questions), but it feels to me that if we can capture and connect community content using deep learning machines, then social will have a real future, rather than becoming a digital echo of older broadcast models.
Leave a Reply
You must be logged in to post a comment.